So Many Tools, So Many Apps, So Little Visibility!
If you’re not using packets for observability, you’re flying blind.

If the recent nationwide CrowdStrike outage has taught us anything, it’s that enterprises must be prepared for anything and everything. This only goes to reinforce the importance of observability, which is crucial for IT teams who need to respond rapidly to problems within mission-critical network and application systems.
In this blog series, we took a look at how unified-communications-and-collaboration-as-a-service (UCaaS) and software-as-a-service (SaaS) tools are being used at enterprises today and at some of the common problems IT faces. In our first blog, we looked at the results of the latest NETSCOUT UCaaS Survey, which showed the prevalence of UCaaS as a vital communication tool for businesses. Respondents to the survey indicated they are using at least one UCaaS tool in their company, with nearly 60 percent of them using six or more tools. What’s more, over 70 percent said their businesses plan to increase the number of UCaaS tools in use. This is proof positive that UCaaS has become essential for productivity and instrumental in meeting the evolving needs of businesses—thus putting more pressure on IT teams to keep things up and running smoothly.
An Abundance of Tools Brings a Plethora of Problems
In the second blog in this series, we shared this year’s survey results, which were expanded to include the widespread use of SaaS tools. The survey found that 90 percent of companies have six or more SaaS tools in their environment. With this growing abundance of tools comes inevitable performance problems, which can threaten to prevent users from conducting business as usual. Not surprisingly, nearly all survey participants felt that user experience issues impact the value of both UCaaS tools and SaaS platforms.
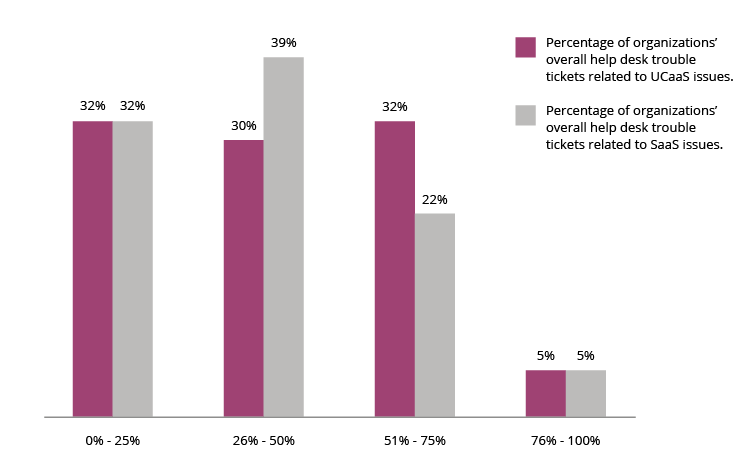
Digging a little deeper, in our fourth blog in the series, survey respondents indicated that problems with UCaaS and SaaS represent a significant portion of overall help desk trouble tickets. An increasingly large amount of IT teams’ time is being spent dealing with these issues, which in turn keeps them from addressing other pressing IT problems within the organization, further stretching already limited resources.
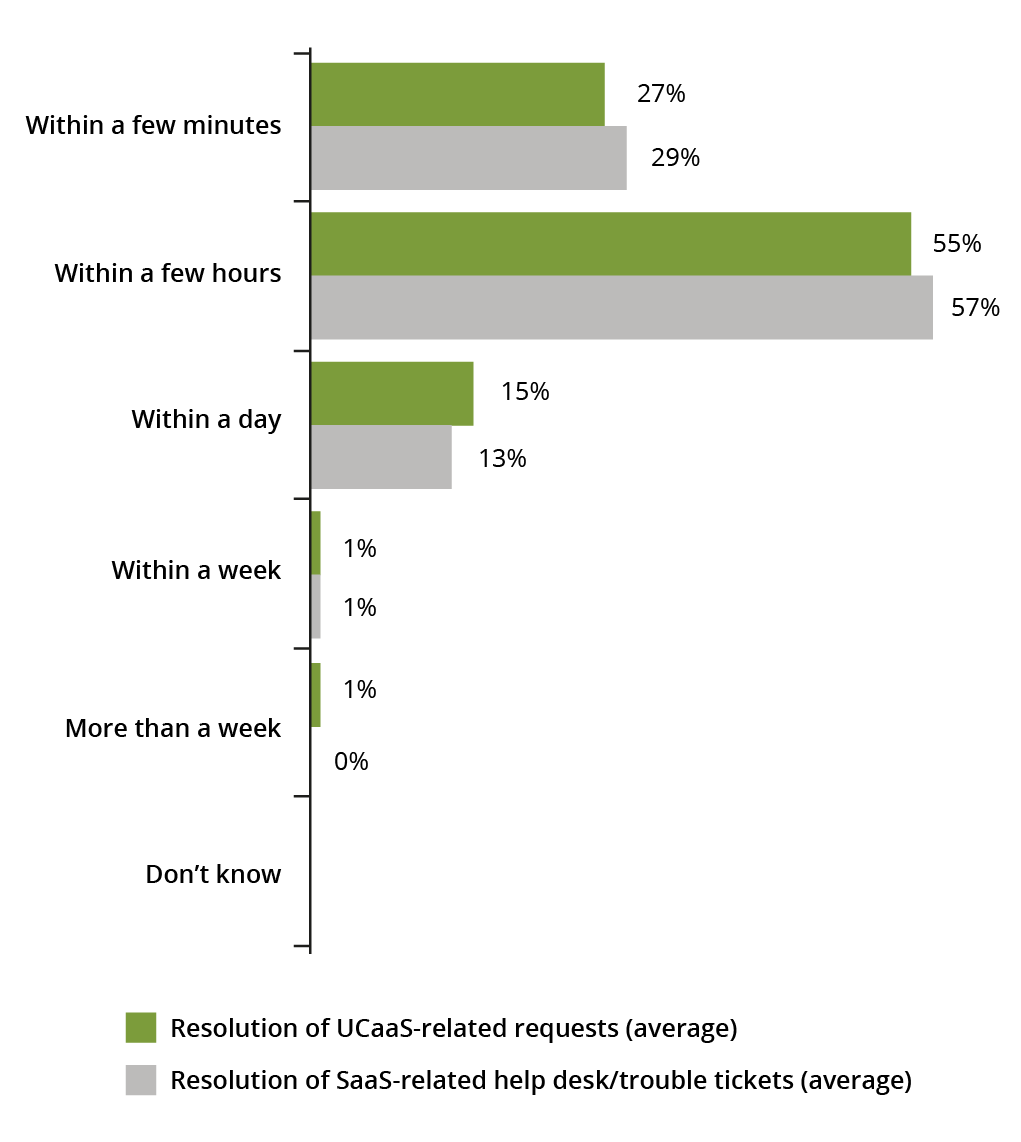
The Long and the Short of It: Pinpointing and Resolving Problems Takes Too Long
Without sufficient visibility into complex networks, IT is behind the eight ball when it comes to quickly pinpointing and resolving problems. This means business is interrupted for longer periods of time, and frustration with IT can build. Our fifth blog examined this issue. The NETSCOUT survey found that for 72 percent of respondents, it takes IT from a few hours to as much as a week to resolve UCaaS issues. Similarly, 71 percent indicated it takes the same length of time to resolve SaaS-related issues. The fact that less than a third of trouble tickets for UCaaS (27 percent) and SaaS (29 percent) can be quickly resolved is an unacceptable situation that adversely impacts business continuity and productivity. It’s no wonder IT professionals are feeling so stressed these days!
IT’s Worst Nightmare: The Staggering Cost of Downtime
As with any other IT-related system outage, when UCaaS tools or SaaS applications go down, the business is instantly in trouble—and that’s the nightmare scenario for IT teams. Worst of all, this is an increasingly common problem. The survey revealed that 96 percent of IT professionals experienced an outage in the last year. 50 percent indicated their organization had experienced four or more outages in the past year. Such outages can be devastating. 64 percent of respondents stated these interruptions cost their business $10,000 or more. In today’s highly cost-conscious environment, losses such as these are intolerable.

Using Vendor-Only Tools Is a Recipe for Failure: A Better Approach is Needed
The staggeringly high cost of downtime, along with the unabated frequency and length of outages, begs a question: How are organizations troubleshooting problems in their environments today? Most IT organizations are overwhelmed by the sheer magnitude and complexity of the problems they face. And the tools that are available are simply inadequate. The survey found that 83 percent of IT teams are using the UCaaS vendor’s proprietary monitoring/analysis tool for evaluating performance and troubleshooting their own platform. Such tools are simply unable to identify problems that spread beyond the confines of the vendor’s platform.
When stuck using vendor-only tools that lack broader observability, IT ends up with an incomplete picture and an inability to effectively pinpoint problems. Even when packets are the data source used via a UCaaS vendor’s monitoring tools, there will be gaps in visibility. This highlights the need for a better approach—one that uses a vendor-independent, third-party solution for monitoring and troubleshooting at the packet level across the overall communications path, not just a portion. The NETSCOUT survey revealed that only 23 percent of respondents are currently using such an approach. Surprisingly, this is the same percentage revealed in last year’s survey.
The Definition of Insanity: Doing the Same Thing Over and Over and Expecting a Different Outcome
The fact that the use of proven, vendor-independent third-party monitoring has not changed year over year is surprising. As a result, there has been no meaningful improvement in the mean-time-to-resolve (MTTR) problems. And that’s hard to reconcile, given all that is at stake.
The cost of downtime, loss of productivity, and damage to user experience alone would suggest a course correction is needed. Doing the same thing year after year to troubleshoot UCaaS and SaaS issues with the unfulfilled expectation of having a different outcome is the literal definition of insanity. Of course, no one is accusing IT of being insane, but clearly, a different approach is called for.
There Has Got to Be a Better Way. Fortunately, There Is!
IT departments clearly need an independent, packet-based observability solution that can more effectively monitor communication paths throughout the entire network ecosystem, allowing them to examine critical factors, such as call quality and quality-of-service (QoS) priority settings.
NETSCOUT offers a best-in-class, packet-based, vendor-independent, end-through-end monitoring solution that quickly pinpoints problems, provides early warning into issues that might cause interruptions or degradations of service, detects problems within a third-party vendor’s infrastructure, and most importantly, helps reduce overall MTTR. This industry-leading deep packet inspection–powered solution, nGenius Enterprise Performance Management, also enables mean opinion score (MOS) analysis and synthetic testing for end-user experience analysis, allowing IT to ensure unified communications and collaboration (UC&C) and UCaaS quality. Further, it is able to provide observability throughout the overall communications path to pinpoint the true root cause of the problem, not simply rule out a portion of the ecosystem. This reduces MTTR, and that in turn will reduce the impact and potential costs for downtime that go longer than they should. That has real value to your customers, reputation, and bottom line.
See all the trends for UCaaS, SaaS, contact centers, and remote sites in our comprehensive report “UCaaS and Today’s Enterprise: The True Cost of Outages and Help Desk Support.”